Quick example on how to easily send a file using Zend Framework's Zend_Mail class.
Hour long tutorial going over the basics of using git. Great for beginners, and instructive for intermediate users looking to fill in gaps in their knowledge about Git. Tom Preston-Werner is co-founder of Github.
I wanted to see which images I had in a directory that were a certain set resolution and decided to see how easy it was to do in ruby.
Turns out with a little
gem install image_size
It's pretty easy!
With Eclipse Indigo finally released it also means time to reinstall our favourite extensions and plugins.
Personally, I maintain a fairly vanilla setup. I use the PHP Developer Tools, E/JGIt plugins and Subclipse for SVN.
To get hold of these packages add the following two update sites after installing indigo.
- http://download.eclipse.org/releases/indigo - Egit and PDT 3
- http://subclipse.tigris.org/update_1.6.x - Subclipse SVN (much better than Subversive)
Foolishly, when working on a recent gateway implementation (usaepay) I wrote a custom logging function to keep track of what was happening.
Turns out there's already something there to do it
Mage_Payment_Method_Abstract::_debug($data);
If you want to call it from outside the payment_method inheritance tree use
Mage_Payment_Method_Abstract::debugData($data);
In both cases your payment method needs to have its debug config setting enabled e.g. for my usaepay module
echo Mage::getStoreConfig('payment/usaepay/debug');
>> 1
If you have an existing codebase and it's already in a git repository there's a number of ways to get it into github (or any other remote git repository). Many of these involve losing your branch history and creating a brand new repository.
This is where the git remote add command comes in handy.
$ git remote add origin [email protected]:ajbonner/foo.git
You can see the remotes associated with your branch:
$ git remote -v
>> origin [email protected]:ajbonner/foo.git (fetch)
>> origin [email protected]:ajbonner/foo.git (push)
To push the existing code to the remote:
$ git push origin master
You now have set up the remote and pushed your master branch into it. From here it gets tricky because subsequent git pull requests will give you an ugly error
$ git pull
>> You asked me to pull without telling me which branch you
want to merge with, and 'branch.master.merge' in
your configuration file does not tell me, either. Please
specify which branch you want to use on the command line and
try again (e.g. 'git pull <repository> <refspec>').
See git-pull(1) for details.
If you often merge with the same branch, you may want to
use something like the following in your configuration file:
[branch "master"]
remote = <nickname>
merge = <remote-ref>
[remote "<nickname>"]
url = <url>
fetch = <refspec>
See git-config(1) for details.
There a few ways to get around this:
Follow the directions given by git and edit your gitconfig
Clone a fresh copy of the master branch from the remote
When defining the remote add the --track option and give it the name of the master branch
$ git remote add --track master origin [email protected]:ajbonner/foo.git
4 Refer to the remote branch using --set-upstream
$ git branch --set-upstream master origin/master
Personally I find option number 4 the best with the least amount of work.
You can also use:
$ git config --global branch.autosetupmerge true
To avoid having to do this.
Magento is a complicated piece of ecommerce software that has been in the past notoriously difficult to employ TDD practices on. Luckily in the past few months we've had Alistair Stead's Mage_Test and now Ivan Chepurnyi's EcomDev PHPUnit Suite testing frameworks released, to make this a little less difficult.
On my most recent project I exclusively employed Mage_Test for my Unit Testing and with a few exceptions, it's performed extremely well.
Mage_Test takes a very hands-off, light-weight approach. EcomDev meanwhile, on the surface, appears to provide far greater support for testing at the expense of some complexity.
Installing EcomDev's Test module is easy. You can install it from Magento Connect or you can get the module directly from the developer's Subversion repository
$ svn co http://svn.ecomdev.org/svn/ecomdev-phpunit/trunk
Once you have the code, it's just a matter of copying into your magento store as with any other module:
$ cp -r <ecomdevtestdir>/* path/to/your/magento/rootdir
Once the files are in place, you'll need to edit app/etc/local.xml.phpunit and supply some details for a test database connection and some path information relating to the store site root URIs.
Once your database and paths have been defined initialise the test database by changing into your store root and running the UnitTests.php test suite
~/Sites/my/store/root: $ phpunit UnitTests.php
This will take some time (one of my clients has a 400meg database and a lot of orders, it took ~ 4 minutes).
You're now ready to start writing some tests.
For more information on EcomDev's PHPUnit module see this blog post or get a copy of the (very) comprehensive EcomDev PHPUnit 0.20 Manual
Yesterday on Twitter someone asked if there was a way to export data from mysql, but only from tables matching a like pattern. E.g. something like
mysqldump -uuser -p mydb mytables_*
There isn't an inbuilt mechanism to do this, my reply was to use a shell script with an array containing a list of tables you wanted to export. Another reply had a better way, using a call to mysql to get a list of tables matching a glob pattern, putting them in an array and then iterating over that array with successive calls to mysqldump.
I put this suggestion together with mine, made it more generic and popped it on github for reference.
Personally I've placed this in my user's .bash_functions (included by .bashrc).
Edited 10th June '11 - use update site: http://download.eclipse.org/egit/updates
There is an issue at the moment when you try and install the egit/jgit plugins with Indigo versions RC3 and above.
You'll encounter an error similar to this:
An error occurred while collecting items to be installed session context was:(profile=epp.package.rcp, phase=org.eclipse.equinox.internal.p2.engine.phases.Collect, operand=, action=). No repository found containing: osgi.bundle,org.eclipse.egit,1.0.0.201106011211-rc3 No repository found containing: osgi.bundle,org.eclipse.egit.core,1.0.0.201106011211-rc3 No repository found containing: osgi.bundle,org.eclipse.egit.doc,1.0.0.201106011211-rc3 No repository found containing: osgi.bundle,org.eclipse.egit.ui,1.0.0.201106011211-rc3 No repository found containing: osgi.bundle,org.eclipse.jgit,1.0.0.201106011211-rc3
This is caused by the latest jgit packages not yet being in the indigo release p2 update repository. To get these installed until these updates are provided, add http://download.eclipse.org/egit/staging/ as an update site and you'll be able to install these plugins successfully.
I found this solution here: https://bugs.eclipse.org/bugs/show_bug.cgi?id=348183
In PHP it's very common to use a variable as an associative array key:
$keys = array('mykey', 'another_key');
$array = array();
foreach ($keys AS $key) { $array[$key] = "hello world\n"; }
foreach ($keys AS $key) { echo $array[$key]; }
>> hello world
hello world
In Ruby, the presence (and use of Symbols) makes this a bit tricky:
keys = ['mykey', 'another_key']
myarray = { :mykey => 'hello world', 'another_key' => 'goodbye world' }
myarray.each { |k|
puts myarray[k]
}
>> hello world
goodbye world
Now if we try this again using instead the Strings from the keys array we get a different result:
keys.each { |k|
puts myarray[k]
}
>>
goodbye world
We don't get the first array value back because a String key is not the same as a Symbol key, even if they consist of the same sequence of characters. This is one of the gotchyas with Ruby.
In Ruby the 'value of a Symbol is not the same as that of a String. So :key != "key". From an ease of use perspective it would be convenient if they did.
Thankfully the language stewards saw fit to include String.to_sym as a convenience method to create a Symbol from a String's value.
keys.each { |k|
puts myarray[k.to_sym]
}
>> hello world
It's very simple right now to get the milestone builds of the PHP Developer Tools (PDT) 3 up and running (and a significant improvement on the current Helios SR2 release).
Pull down the 'classic' version Eclipse 3.7 Indigo from http://www.eclipse.org/downloads/ and install.
Once installed, launch Eclipse and navigate to Help->Install new Software.
Add the Indigo update site 'http://download.eclipse.org/releases/indigo'. This will take sometime to add, let it go for 5 or so minutes.
UPDATE 20/10/2011
The following step is no longer required as the the PDT 3.0 series is now in the main indigo update repository. Once the Indigo Update Site is added, add the PDT 3.0 Update Site http://download.eclipse.org/tools/pdt/updates/3.0/milestones/
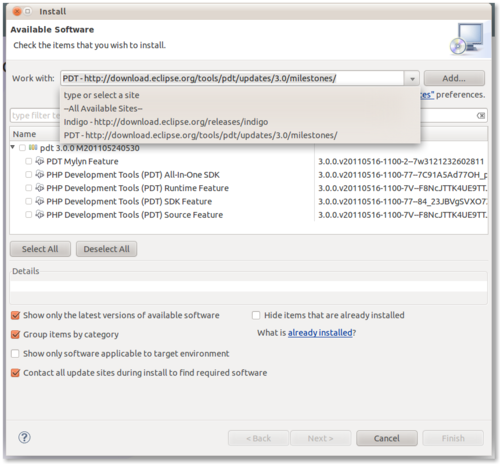
Now, to install simply select PDT Development Tools All in One SDK (leave the others unselected) and click next. The installation process shouldn't take more than a few minutes.
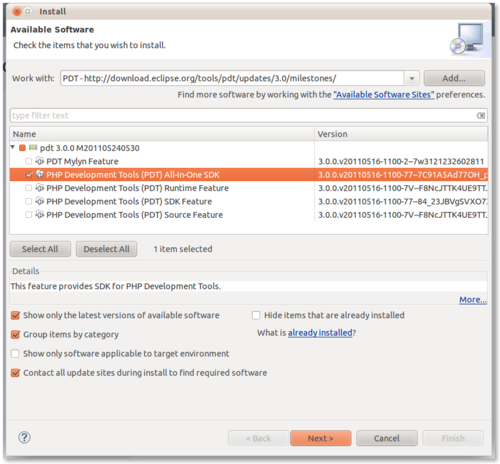 .
.
In these formative stages of my experience with Ruby, one feature of the language that I keep feeling on uneven ground with are Symbols.
I had a feeling I should give them respect as much of the learning Ruby literature says to basically ignore them for now, or launch into lengthy defences of why they exist (usually forgetting to explain how they work).
In case you're unfamiliar with Ruby syntax, a Symbol looks like this
:a_symbol
With the numerous ways of defining variables in Ruby this is another variable looking constuct, except that it isn't actually a variable at all (you cannot assign to it).
So what is a Symbol, actually. To be honest I'm still struggling for a good simple definition. I think the best way to think of it, is as a constant (i.e. immutable) placeholder for the name of something. Or more practically put, a colon in front of the string you want to use for a hashkey. Agile Programming With Rails 4th Ed puts it simply 'a Symbol is a name for something'.
I wrote on Twitter that I felt Symbols were extra syntax put in to solve a problem a programmer in a high level interpreted language shouldn't have to worry about. Memory management. In Ruby everything is an object, and objects are much bigger than the primitives you have in Java, C or even PHP. A string for example in PHP (and as in C) is still ultimately a sequence of bytes stored in contiguous memory addresses. In Ruby, a string is always an object, and that requires a fair chunk of memory to represent. If you have a bunch of hash tables, using objects as a hashkey is inefficient and wasteful.
Symbols help solve this inefficiency. A Symbol is still an object, but a special one. It has few methods the main ones being to get its string value and another its integer value, it's immutable and there's only ever one copy of it. So it's much more efficient to use a symbol as a hashkey than a Ruby string. In Ruby (and most OO languges) two strings even if consisting of the same sequence of characters are different objects. In Ruby two symbols of the same sequence of characters are the same object. In large applications this feature can save a tremendous amout of memory.
The other key characteristic of Symbols is immutability. Symbols cannot be assigned to, they just are. In a language that lacks a true constant construct (uppercasing a variable name is the convention for defining a Ruby constant but read-only access isn't enforced at runtime, you can write to what Ruby calls a 'constant'), Symbols can be useful.
So are Symbols a good language feature? At this point with my lack of experience with Ruby I don't really feel qualified to answer that yet definitively. My gut though, says no. I feel in a high level language the need for extra syntax to optimise code adds an unnecessary burden on the programmer. They seem so out of place in a language that works so hard to strip away unneccessary syntax. Symbols, to me detract from Ruby's power to define elegant and natural sounding expressions.
The difficulty authors have in describing what Symbols are, how to use them and why they should be used seems like a language design smell to me. I dare say as I become more familiar and accustomed to the presence and use of Symbols I'll learn to accept them. But as a Developer new to Ruby, they seem out of place.
I haven't gone into an excessive amount of detail about the nature and application of Symbols. For that the two best resources I've found explaining are http://glu.ttono.us/articles/2005/08/19/understanding-ruby-symbols and http://www.troubleshooters.com/codecorn/ruby/symbols.htm.
$ alias ql='qlmanage -p "$@" >& /dev/null'
Working with PHP websites you’ll regularly need to export/import copies of MySQL databases, whether for testing and debug purposes or at a minimum creating and restoring backups. As database sizes increase this poses risks particularly, for example, with large innodb based applications like Magento where database sizes can easily go into the gigabytes.
The Basics
The process for creating and restoring a snapshot is trivial
$ mysqldump -uuser -p mydatabase > mydump.sql # export
$ mysql -uuser -p mydatabase < mydump.sql # import
For the most part this works as you expect it to, and for small databases this is probably all that is needed. You may find the resultant .sql file is huge, it is after all uncompressed text, at 1 byte per character if the output is ANSI or up to 4 bytes if your character set is UTF-8. Bzip2 will bring the file size down a considerable amount but it’s also considerably slower than gzip.
It’s sometimes tempting to gzip/bzip2 your datadump while performing the mysqldump in a single line.
$ mysqldump -uuser -p mydatabase | bzip2 -c > mydump.sql.bz2
While it seems a nice efficient way to do your backup, this should be avoided as (by default in MyISAM) you’re locking tables and denying other clients access to them. InnoDB implements row level locking which is slightly less offensive, but still should be avoided as much as possible.
When importing a large database, the choice of zip format is important. You have to trade off decompression speed, with filesize. The extra cputime consumed decompressing a bzip2 datadump may actually be less preferable to a few extra megabytes gained by using the faster gzip. Whatever your choice, importing a zipped datadump is very easy.
$ gunzip -c mydump.sql.gz | mysql -uuuser -p mydatabase # importing a gzipped datadump
$ bunzip2 -c mydump.sql.bz2 | mysql -uuuser -p mydatabase # importing a bzip2 datadump
Locking and Transactional Integrity
As explained briefly above, MySQL’s storage engines come with some limitations. In the worst case, with MyISAM, while performing a mysqldump entire tables will be locked, that means other clients will not be permitted to write to a table while the dump is being performed. If you have large MyISAM tables this poses clear problems when backing up a running application.
InnoDB is slightly better because it uses row level locking. It locks only the rows affected by a query, and not the whole table. This makes a conflict far less likely to occur while performing a backup on a running application. InnoDB as a transactional storage engine does allow for the possibility that active transactions may be underway while you’re attempting your backup.
Two options we can pass to mysqldump mitigate these issues are, —single-transaction and —skip-lock-tables.
$ mysqldump --single-transaction --skip-lock-tables mysql -uuser -p mydatabase
The use of —single-transaction means mysql issues a begin statement before dumping the contents of a table, ensuring a consistent state of the table without blocking other applications. It means writes can occur while the backup is taking place and this will not affect the backup. The —skip-lock-tables option stops MyISAM tables being locked during the backup. This does mean the integrity of the table can be lost as writes occur to them during the backup process. The risk is weighed up against the risk of blocking access to the table during a lengthy backup process.
Improving Import Performance
Choice of zip format will have a large bearing on import performance. Gzip is appreciably faster than bzip2. Other options you can pass to mysqldump to improve import performance are —disable-keys and —no-autocommit.
Disabling keys significantly improves the performance of imports as mysql will only index the table at the end of the import. With keys enabled, the index is updated after each row is inserted. Given you are performing a batch import, this is suboptimal.
By default each statement in an InnoDB table is autocommitted. This comes with unneccessary overhead when performing a batch import as you really only need to commit once the table has been fully imported.
Further Reading
This only a brief look at using Mysqldump for backups. It’s a common enough development task that all developers should take the time to see how it can be best leveraged for their environment. There’s plenty of documentation out there on using the tool. But the best place to start is with the official docs.
Page 6 of 15
Previous page