By now, I'm pretty much used to and accept OSX as a desktop operating system. I remember it being quite a change when I first moved over (from Gentoo linux and Gnome 2). The mouse movement was wonky, I had to overcome years of muscle memory (learning to use the cmd instead of control key), and probably hardest of all, was leaving behind Unix's idea of workspaces and virtual desktops. What I gave up in configurability though, was more than made up for by consistency and stability. Colleagues of mine can attest to the number of expletives launched at an emerge -vuND world that detonated my Gentoo Desktop.
So I'm happy with a less flexible, but attractive, functional and predictable desktop and I think many others feel the same way. It's no real surprise to me then, that OSX has mostly killed off the idea of Linux on the Desktop.
But somewhere that OSX falls severely behind, is its use of a BSD inspired Unix implementation. If you're born and raised on a diet of GNU (file|core)utils, of apt, yum, and portage, heck even sysvinit, OSX's realisation of Unix leaves a lot to be desired.
With considerable effort and some patience though, OSX can be brought to heel. With Iterm2 and Macports you can have a functional GNUlike Unix experience.
I'll go over the minutiae of my Macports setup another time, but generally speaking I replace all the default OSX tools with GNU equivalents and favour /opt/local/bin over everything else. It means I can have one set of configs which work mostly unchanged across Linux and OSX instances.
Macports is pretty good and the folks that contribute to it do a great job. But it does lack the polish that you take for granted with the Linux package managers. Another point to keep in mind is Macports, like Portage and BSD Ports, is a source-code based 'package' manager. When you install something, it is compiled right there and then on your system. When things go wrong, unless you're a competent C programmer (and even then) you're going to have a bad time.
One last thing to remember too, is OSX defaults to a case insensitive (but thankfully case-preserving) HFS filesystem. By default, PHP and php appear as the same thing to HFS.
So the point of this blog is to go over getting PHP running natively with Macports and how we can run an instance of Magento and the Magento Test Automation Framework (TAF).
MySQL
MySQL is probably the easiet part of the whole thing to setup. So let's start there. For reference, the database files are stored under /opt/local/var/db/mysql55.
In Macports MySQL carrys a namespace of sorts by the way of a version suffix (as does PHP). This lets multiple versions of a package be installed side-by-side. The drawback is rather than having a mysql command, you have a mysql55 command. That's annoying. So we will install mysql_select which lets us select a version to activate and give us proper file names.
$ sudo port install mysql55-server mysql55 mysql_select
$ sudo port select mysql mysql55
$ sudo port load mysql55-server
We will want a database for our magento application.
$ mysqladmin -uroot -p create magento
PHP / PHP-FPM
Now we want to install PHP, PHP-FPM and the extensions Magento and TAF require.
$ sudo port install php54 php54-fpm php54-curl php54-APC php54-gd php54-pcntl php54-gd php54-mcrypt php54-iconv php54-soap php54-yaml php54-xdebug php54-openssl php54-mysql php54-pear php_select pear-PEAR
$ cd /opt/local/etc/php54
$ cp php-fpm.conf.default php-fpm.conf
$ cp php.ini-development php.ini
$ sudo vim php.ini
# set date.timezone and cgi.fix_pathinfo = 0
$ sudo vim php-fpm.conf
# make any changes for min / max num servers, error logging etc
The MySQL extension needs a little bit of prodding to look in the correct location for mysql.sock
echo 'pdo_mysql.default_socket=/opt/local/var/run/mysql55/mysqld.sock' | sudo tee --append /opt/local/var/db/mysql.ini
Once PHP-FPM is installed and configured you can use Macports to tell launchd to start it automatically.
$ sudo port load php54-fpm
PHP-Select
As with MySQL, Macports lets you install multiple versions of PHP side by side. This can be handy if you want to run PHP 5.3 and PHP 5.4 at the same time. I just install a single version, but Macports effectively namespaces everything. So rather than '/opt/local/bin/php' you have '/opt/local/bin/php54'. PHP Select, which we installed earlier fixes this by effectively 'activating' one version and creating the usual executable names we're accustomed to.
$ sudo port select php php54
PEAR
PEAR is the single biggest pain in the whole process. And with some research it turns out its because Macports PEAR isn't even meant be used by end users (WAT?!).
There is no MacPorts port that installs the pear package manager application with the intent that it be used by the end user outside a MacPorts port install. If you want to use pear manually on your own then you should install it using gopear, composer or some other method.
http://trac.macports.org/ticket/37683
So this goes a long way to explaining why Macports doesn't set PEAR up with sane defaults, or even put the pear command in the default path. But we can sort this all out easily enough ourselves.
$ sudo pear config-set php_bin /opt/local/bin/php
$ sudo pear config-set php_dir /opt/local/lib/php/pear
$ sudo pear config-set ext_dir /opt/local/lib/php54/extensions/no-debug-non-zts-20100525
$ sudo pear config-set bin_dir /opt/local/bin
$ sudo pear config-set cfg_dir /opt/local/lib/php/pear/cfg
$ sudo pear config-set doc_dir /opt/local/lib/php/pear/docs
$ sudo pear config-set www_dir /opt/local/lib/php/pear/www
$ sudo pear config-set test_dir /opt/local/lib/php/pear/tests
$ sudo pear config-set data_dir /opt/local/lib/php/pear/data
$ echo 'PATH=$PATH:/opt/local/lib/php/pear/bin' >> ~/.bashrc # or zshrc if you use zsh
Another issue you'll possibly have with PEAR, is it will default to the system PHP executable (/usr/bin/php) rather than your active Macports one. The pear command does test for an environment variable so we can set up an alias to pass this variable to pear on invocation.
Add an alias to your bashrc/zshrc in the form:
alias pear='PHP_PEAR_PHP_BIN=php pear'
Reload your bashrc/zshrc.
$ source .bashrc (or source .zshrc)
Now the alias is active we can check that it's working
$ /opt/local/lib/php/pear/bin/pear version
PEAR Version: 1.9.4
PHP Version: 5.3.15
Zend Engine Version: 2.3.0
Running on: Darwin avalanche 12.2.0 Darwin Kernel Version 12.2.0: Sat Aug 25 00:48:52 PDT 2012; root:xnu-2050.18.24~1/RELEASE_X86_64 x86_64
$ pear version
PEAR Version: 1.9.4
PHP Version: 5.4.12
Zend Engine Version: 2.4.0
Running on: Darwin avalanche 12.2.0 Darwin Kernel Version 12.2.0: Sat Aug 25 00:48:52 PDT 2012; root:xnu-2050.18.24~1/RELEASE_X86_64 x86_64
Now to make installing PEAR packages easier I turn the channel autodiscovery option on, which means you don't have to manually add channels for package dependencies (which there are a lot when installing phing or phpunit…)
$ sudo pear config-set auto_discover 1
Now add phing and phpunit and install them with all their optional dependencies and some extra packages for the Magento TAF.
$ sudo pear channel-discover pear.phing.info
$ sudo pear channel-discover pear.phpunit.de
$ sudo pear channel-discover pear.symfony-project.com
$ sudo pear install --alldeps phing/phing
$ sudo pear install --alldeps phpunit/phpunit
$ sudo pear install phpunit/PHP_Invoker
$ sudo pear install phpunit/PHPUnit_Selenium
$ sudo pear install -f symfony/YAML
PECL/Extensions
Macports by default creates .ini files to load extensions in /opt/local/var/db/php54. If you manually build any extensions, add the appropriate ini file here, for example:
$ echo 'extension=yaml.so' | sudo tee /opt/local/var/db/php54/yaml.ini
Nginx
Apache/Nginx. It doesn't really matter. Both are great, but in production I use Nginx so I use it in development too. I install it with just the ssl extension enabled, to see the full range of available options, use:
$ sudo port variants nginx
To install:
$ sudo port install nginx +ssl
$ cd /opt/local/etc/nginx
$ sudo cp fastcgi.conf.default fastcgi.conf
$ sudo cp fastcgi_params.default fastcgi_params
$ sudo cp mime.types.default mime.types
$ sudo cp nginx.conf.default nginx.conf
$ sudo mkdir conf.d sites-available sites-enabled ssl
Once installed, Nginx requires a little bit of work to hook up to PHP and particularly to work well with Magento.
$ sudo vim nginx.conf
# Insert the following towards the bottom of the file (but inside the http block)
map $scheme $fastcgi_https {
default off;
https on;
}
##
# Virtual Host Configs
##
include conf.d/*.conf;
include sites-enabled/*;
For each app just add a server block to sites-available, then symlink it to sites-enabled.
$ sudo vim sites-available/magento.dev.conf
# ...
$ cd sites-enabled
$ sudo ln -s ../sites-available/magento.dev.conf 001-magento.dev.conf
This is the server block definition I use for magento development, feel free to modify it for your needs.
server {
listen 80;
listen 443 ssl;
ssl_certificate ssl/magento.dev.crt;
ssl_certificate_key ssl/magento.dev.key;
server_name magento.dev;
root /Users/aaron/Sites/magento;
location / {
index index.html index.php; ## Allow a static html file to be shown first
try_files $uri $uri/ @handler; ## If missing pass the URI to Magento's front handler
expires 30d; ## Assume all files are cachable
}
## These locations would be hidden by .htaccess normally
location /app/ { deny all; }
location /includes/ { deny all; }
location /lib/ { deny all; }
location /media/downloadable/ { deny all; }
location /pkginfo/ { deny all; }
location /report/config.xml { deny all; }
location /var/ { deny all; }
location /shell/ { deny all; }
## Disable .htaccess and other hidden files
location ~ /\. {
deny all;
access_log off;
log_not_found off;
}
location ~ \.php$ { ## Execute PHP scripts
if (!-e $request_filename) { rewrite / /index.php last; } ## Catch 404s that try_files miss
expires off; ## Do not cache dynamic content
fastcgi_intercept_errors on;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param HTTPS $fastcgi_https;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param MAGE_RUN_CODE default; ## Store code is defined in administration > Configuration > Manage Stores
fastcgi_param MAGE_RUN_TYPE store;
proxy_read_timeout 120;
proxy_connect_timeout 120;
include fastcgi_params; ## See /etc/nginx/fastcgi_params
}
location @handler { ## Magento uses a common front handler
rewrite / /index.php;
}
}
We've said our application lives on a server called 'magento.dev'. So let's tell our hosts file about that.
$ vim /etc/hosts
# Insert or append to an existing line
# 127.0.0.1 localhost magento.dev
Last thing that needs to be done is setting up a selfsigned ssl certificate / key pair and storing them under /opt/local/etc/nginx/ssl
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout myserver.key -out myserver.crt
$ sudo mv myserver.key /opt/local/etc/nginx/etc/ssl/magento.dev.key
$ sudo mv myserver.crt /opt/local/etc/nginx/etc/ssl/magento.dev.crt
Once that's done, we can start nginx.
$ sudo port load nginx
Web App Directory Config
I keep my web apps living under /Users/aaron/Sites, but remember that every directory element in the path needs to have the executable bit set for all users (so the web server can traverse the directory tree). Literally this is a case of:
$ chmod a+x /Users/aaron && chmod a+x /Users/aaron/Sites
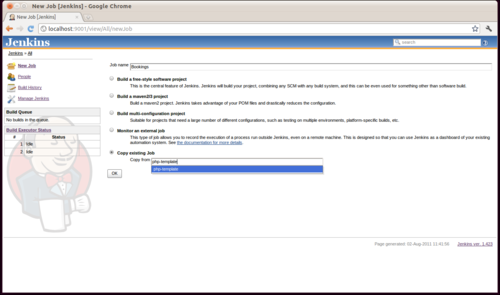
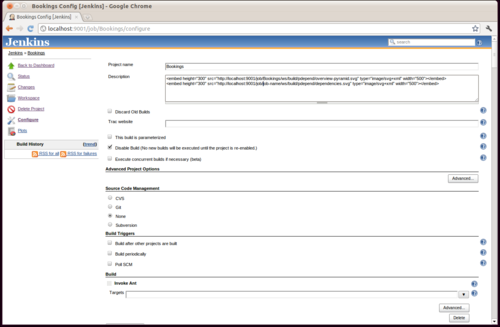
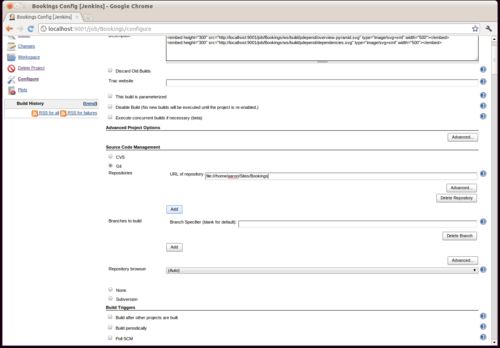
Install Magento and TAF
N98 Magerun is the coolest thing to happen to Magento development since well, I can't remember. It singlehandedly relegated a few thousand lines of cobbled together bash script to the bin.
$ cd /Users/aaron/Sites
$ curl -O magerun.phar https://github.com/netz98/n98-magerun/raw/master/n98-magerun.phar
$ chmod a+x magerun.phar
$ ./magerun.phar install
# Follow the directions and install to /Users/aaron/Sites/magento with base url http://magento.dev and database name 'magento'.
After all that work, hitting http://magento.dev should now bring up the magento demo store!
I've been playing with Magento's Test Automation Framework and it was the motivation for finally getting everything working properly natively.
TAF runs at a glacial pace and in my normal development environment (VirtualBox over NFS), the universe would have undergone heat death long before the TAF suite completed its running.
Unfortunately the documentation for TAF is a bit of a mess (I'll write about my experience with it soon), but what it offers - 1500 automated tests - is a pretty big attraction.
Installation is actually pretty easy. I am assuming you don't have git already installed (remember you can use port variants to see what extension options are available):
$ sudo port install git-core +bash_completion +credential_osxkeychain +doc +pcre +python27
$ sudo port install git-extras
$ cd /Users/aaron/Sites
$ git clone https://github.com/magento/taf taf
$ cd taf # /Users/aaron/Sites/taf
$ cp phpunit.xml.dist phpunit.xml
$ cp config/config.yml.dist config/config.yml
$ cd .. # /Users/aaron/Sites
$ curl -O selenium-server.jar http://selenium.googlecode.com/files/selenium-server-standalone-2.31.0.jar
To run the test suite open up a new terminal
$ cd /Users/aaron/Sites
$ java -jar selenium-server.jar
Now the test suite is good to go
$ cd /Users/aaron/Sites/taf
$ ./runtests.sh
The test suite takes a loooooong time, so go for a run or something.
Hopefully these steps help out other PHP developers suffering from OSX.


 .
.